| +7 (495) 229-0436 | shopadmin@itshop.ru | 119334, г. Москва, ул. Бардина, д. 4, корп. 3 |
|
|
Укрощение терабайта XML-данных08.01.2014 15:37
В настоящее время предприятия изо всех сил стараются организовать управление увеличивающимся объемом данных XML, которые они генерируют и потребляют. Корпорации Intel и IBM провели эталонное тестирование первой в отрасли терабайтной базы данных XML на основании сценария применения в финансовой индустрии. Тестирование показало осуществимость управления большими объемами данных XML на экономичной аппаратной платформе. Не вызывает сомнений тот факт, что XML превратился в фактический стандарт для обмена данными, сервис-ориентированных архитектур (SOA) и обработки транзакций на основе сообщений. По мере роста объема накапливаемых данных XML у компаний возникает потребность в чем-то большем, чем просто технология обработки сообщений, которая единовременно работает с одним документом XML. Компании начали сохранять большие объемы документов XML, иногда для соблюдения требований закона, а иногда - вследствие гибкости XML или из-за широко известных трудностей, связанных с преобразованием данных XML в реляционный формат и обратно. Привыкшие к преимуществам развитых реляционных баз данных, компании ожидают наличия таких же возможностей для данных XML (речь идет о возможностях хранения, запроса, индексирования, обновления и проверки данных XML с полным соответствием принципам ACID, возможностях восстановления, высокой доступности и высокой производительности). XML иногда считают многословным и медленным форматом данных, особенно при обработке большого количества документов. Подобное отношение к XML часто основывается на опыте того времени, когда еще не существовало надлежащих технологий. Например, сохранение множества документов XML в файловой системе и написание кода приложения для их синтаксического разбора и анализа зачастую приводят к неудовлетворительной производительности и являются источником разочарований. Благодаря появлению современных технологий баз данных и процессоров от такого сценария можно отказаться. Используя доступные в DB2 возможности pureXML и многоядерные ЦП Intel, корпорации Intel и IBM провели эталонное тестирование первой в отрасли терабайтной базы данных XML для демонстрации того, что высокопроизводительная обработка транзакций при работе с терабайтом данных XML больше не является беспочвенной фантазией. В настоящей статье описываются эти тесты производительности, используемые аппаратные средства и конфигурация DB2, а также приводятся результаты и разбираются полученные уроки. Свою ключевую роль подтвердили различные технологии DB2, включая глубокое сжатие, автоматическое сохранение данных, память с самонастройкой и, разумеется, pureXML. Результаты позволяют количественно оценить многопользовательскую масштабируемость DB2 с использованием платформы Linux на четырех- и шестиядерных процессорах Intel (процессорах Intel Xeon серий 7300 и 7400). Подготовка конфигураций всех систем и проведение тестов, указанных в настоящей статье, осуществлялись корпорацией Intel в собственной лаборатории. DB2 pureXMLpureXML DB2 обеспечивает поддержку управления данными XML, в том числе хранилище XML, индексацию XML, запросы и обновления XML, а также в качестве опции проверку документов с использованием схем XML. Пользователи могут определять столбцы типа XML, в которых можно сохранять по одному документу XML на строку. Таблицы могут содержать комбинацию XML- и реляционных столбцов, что упрощает интеграцию XML и реляционных данных. Когда документы XML вставляются или загружаются в столбец XML, они подвергаются синтаксическому анализу и сохраняются в проанализированном древовидном формате. Это позволяет выполнять запросы и обновления для работы с данными XML без синтаксического анализа XML, что является одним из ключевых преимуществ с точки зрения производительности. XML можно индексировать по конкретным элементам или атрибутам для достижения высокой производительности запросов. Запросы и обновления основываются на стандартах SQL/XML и XQuery и в случае необходимости могут обращаться в одном операторе как к XML, так и к реляционным данным. Эталонный тест TPoXДля подтверждения высокой производительности XML мы решили провести эталонное тестирование TPoX. TPoX (обработка транзакций по XML) представляет собой эталонный тест базы данных XML с открытым исходным кодом и тест уровня приложения, основанный на сценарии применения в финансовой отрасли. Он оценивает производительность систем баз данных XML, фокусируясь на XQuery, SQL/XML, хранилище и индексации XML, поддержке схем XML, операциях вставки, обновления и удаления XML, регистрации, параллелизме и других аспектах баз данных. TPoX имитирует сценарий торговли ценными бумагами и использует реальную схему XML (FIXML) для моделирования некоторых из своих данных. TPoX разработан для выполнения реалистичного и репрезентативного набора операций с XML. Основными логическими информационными объектами в TPoX являются следующие объекты:
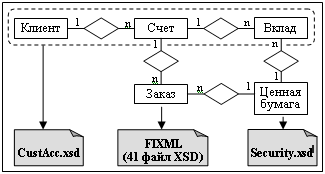
Для каждого клиента имеется документ XML, который содержит всю персональную информацию, информацию о счетах и информацию о вкладах для данного клиента (см. рисунок 1). Каждый заказ представлен сообщением XML, которое соответствует схеме FIXML 4.4. FIXML - это стандартная для отрасли сложная схема XML, предназначенная для сообщений, связанных с биржевой торговлей, например, заказов на покупку или продажу. Каждая ценная бумага описывается с помощью отдельного документа XML. Коллекция из 20833 документов-описаний ценных бумаг представляет большинство акций, облигаций и взаимных фондов, обращающихся в США. Несмотря на то, что количество документов ценных бумаг является фиксированным, сценарий эталонного тестирования масштабируется по количеству документов custacc (клиентский счет) и order (заказ). В базе данных TPoX объемом 1 ТБ используется 300000000 документов order и 60000000 документов custacc. Рисунок 1. Информационные объекты TPoX.
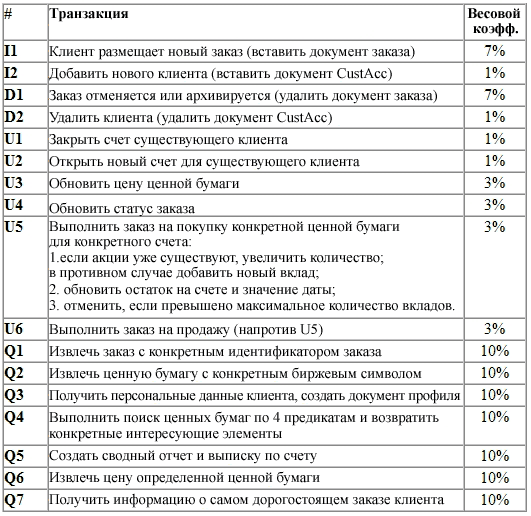
Таблица 1. Бизнес-описания транзакций TPoX.
Рабочая нагрузка выполняется драйвером рабочей нагрузки Java, который порождает конфигурируемое множество параллельных потоков для моделирования одновременных действий нескольких пользователей. Каждый поток подключается к базе данных и выполняет некоторую последовательность транзакций без времени на обдумывание. Когда транзакция фиксируется, поток, зафиксировавший данную транзакцию, незамедлительно выбирает еще одну транзакцию из таблицы 1 (выбор осуществляется случайным образом с асимметричным распределением вероятностей, учитывающим весовые коэффициенты транзакций). Во время выполнения драйвер рабочей нагрузки заменяет маркеры параметров в транзакциях конкретными значениями, извлекаемыми из случайных распределений. Код Java драйвера рабочей нагрузки доступен в виде открытого исходного кода и может использоваться для разнообразных тестов баз данных, а не только для эталонного тестирования TPoX. Тестируемая системаТестовая система (рисунок 2) состоит из следующих аппаратных и программных компонентов:
Рисунок 2. Тестируемая система.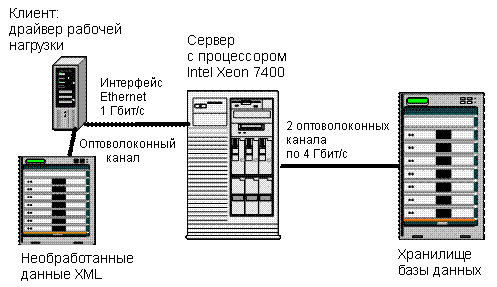 Процессоры Intel Xeon серий 7400 и 7300Для анализа масштабируемости производительности DB2 с увеличением количества ядер на один ЦП мы выполнили эталонное тестирование дважды с использованием разных процессоров. При проведении первого набора тестов использовались четыре ЦП Intel Xeon серии 7400 с шестью ядрами каждый. Затем мы повторили эталонное тестирование с использованием четырех ЦП Intel Xeon 7300 с четырьмя ядрами каждый. Приведенное в таблице 2 сравнение показывает, что ЦП отличаются друг от друга не только количеством ядер. Несмотря на то, что процессор Intel Xeon серии 7400 имеет на 50 процентов больше ядер, чем процессор серии 7300, его тактовая частота на 10 процентов ниже. Однако при этом он имеет кэш 3-го уровня объемом 16 МБ, в то время как у процессора Intel Xeon серии 7300 подобный кэш отсутствует. Таблица 2. Процессоры Intel Xeon, которые использовались при проведении данного эталонного тестирования.
При замене ЦП все остальные аппаратные и программные средства оставались прежними. В процессорах Xeon серий 7400 и 7300 используется одинаковый чипсет, поэтому замена одного процессора другим представляет собой простую "перестановку", не требующую внесения каких-либо других изменений. Конфигурирование и точная настройка DB2База данных DB2 была создана с функцией автоматического хранилища DB2 и размером страниц 16 КБ, с использованием восьми логических томов и одним дополнительным томом для журнала. Схема базы данных, выбранная нами для реализации сценария TPoX, является крайне простой. Она состоит из трех столбцов XML в трех таблицах, по одной для каждого из трех типов документов XML в TPoX (order, custacc, security): create table custacc (cadoc xml inline length 16288) in custacc_tbs index in custacc_idx_tbs compress yes; create table order (odoc xml inline length 16288) in orders_tbs index in orders_idx_tbs compress yes; create table security (sdoc xml inline length 16288) in security_tbs index in security_tbs compress yes; В целях уменьшения пространства хранилища для 1 ТБ необработанных данных XML применялись подстановка и сжатие XML. Мы создали пять табличных пространств (по одному табличному пространству для каждой из трех таблиц, а также одно табличное пространство для индексов custacc и одно для индексов order). Все табличные пространства были сконфигурированы с параметрами NO FILE SYSTEM CACHING ("Без кэширования файловой системы") и AUTOMATIC STORAGE ("Автоматическое хранилище"). Каждое табличное пространство имеет свой собственный буферный пул. Кроме того, имеется один дополнительный буферный пул для временного табличного пространства. Мы использовали разные табличные пространства и буферные пулы главным образом для удобства мониторинга. Впоследствии нами было подтверждено, что при объединении всех таблиц и всех индексов в одно табличное пространство и один большой буферный пул производительность практически не изменилась (пропускная способность снизилась всего на 6 процентов по сравнению с ручным конфигурированием). Для конфигурирования размеров буферных пулов, кучи сортировки, списка блокировок, кэша пакетов, num_iocleaner, num_ioserver и т. д. мы применили следующий подход. Во избежание длительных и повторяющихся итераций точной настройки мы, исходя из разумных предположений, просто задали значения для всех указанных параметров. Выбранные нами показатели не задумывались как оптимальные для данной рабочей нагрузки, и нам не было известно о том, являются ли они таковыми. Они всего лишь играли роль отправной точки для самонастройки DB2. Например, мы знали, что нам необходимы большие буферные пулы для таблиц custacc и order, но нам не было известно о том, какие размеры могли бы быть оптимальными. Мы решили предоставить вычисление оптимального размера самонастраивающемуся диспетчеру памяти (STMM) DB2. Мы не хотели начинать с установленного по умолчанию значения 1000 страниц, поскольку знали, что это слишком мало. Мы хотели помочь STMM быстро прийти к оптимальным размерам буферных пулов. Например, сначала мы установили размер буферного пула для таблицы custacc равным 770000 страниц, а затем выбрали автоматическое определение размера, чтобы потребовалось меньше итеративных регулировок STMM для достижения оптимального размера по сравнению с 1000 страниц. Для настройки параметров INSTANCE_MEMORY и DATABASE_MEMORY также был выбран автоматический режим.
Теперь давайте взглянем на следующие виды итоговых данных:
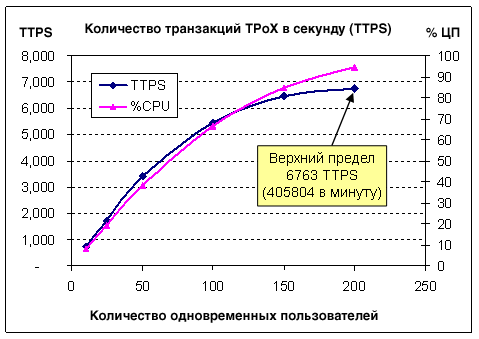
Результаты в отношении расхода ресурсов хранилища и сжатияПоскольку размер таблицы security очень мал (20833 документа), мы изучали расход дискового пространства и коэффициент сжатия главным образом для двух больших таблиц - custacc и order (см. Таблицу 3). 60 миллионов документов custacc сжимаются на 64 процента и требуют 121,4 ГБ в табличном пространстве DB2. 300 миллионов документов order сжимаются на 57 процентов и требуют 269,2 ГБ в DB2. С учетом всех данных и индексов итоговый размер базы данных составлял примерно 440 ГБ. Подстановка и сжатие XML играли критически важную роль в решении проблемы нехватки ресурсов ввода-вывода. Таблица 3. Расход дискового пространства и сжатие Пропускная способность транзакций смешанной рабочей нагрузкиНа рисунке 3 показан результат для пропускной способности транзакций смешанной рабочей нагрузки на 24-ядерной платформе Intel Xeon 7400 с тактовой частотой 2,66 ГГц. По горизонтальной оси показано меняющееся число одновременных пользователей, которое моделирует драйвер рабочих нагрузок TPoX. Каждый пользователь выдает поток транзакций без времени на обдумывание между транзакциями. Синяя кривая представляет количество транзакций в секунду и относится к вертикальной оси, расположенной слева. Розовая кривая показывает использование ресурсов ЦП и относится к вертикальной оси, расположенной справа. Пропускная способность и использование ресурсов ЦП возрастают по мере увеличения количества одновременных пользователей. Когда число пользователей увеличивается с 100 до 150 и 200, использование ресурсов ЦП приближается к уровню максимальной вычислительной мощности системы, и рост пропускной способности замедляется. При 200 пользователях максимальная пропускная способность составляет 6763 транзакции TPoX в секунду. Рисунок 3. Количество транзакций в секунду и использование ресурсов ЦП.
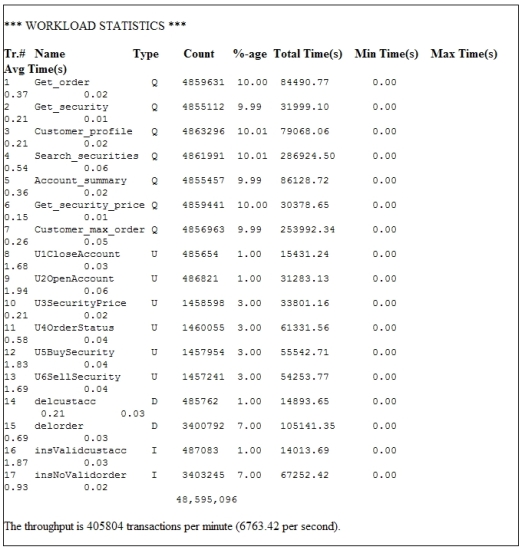
Увеличение количества пользователей сверх 200 не приводит к росту пропускной способности, при этом лишь увеличивается время реакции транзакций. Выравнивание кривой пропускной способности и исчерпание вычислительной мощности системы при 200 пользователях напрямую связаны с тем фактом, что все моделируемые пользователи отправляют транзакции без времени на обдумывание между ними. Если бы каждый пользователь отправлял, например, по одной транзакции в секунду, система могла бы поддерживать тысячи пользователей. На рисунке 4 показаны выходные данные драйвера рабочей нагрузки для смешанной рабочей нагрузки при 200 пользователях и длительности теста 2 часа. Подробная статистика по всем 17 транзакциям в структуре рабочей нагрузки включает их максимальное и среднее время отклика, а также их "число", т. е. информацию о том, сколько раз выполнялась каждая транзакция по всем 200 пользователям. В течение двухчасового теста было выполнено 48,5 миллионов транзакций. Среднее время отклика всех транзакций составило менее 0,1 секунды. Поскольку драйвер рабочей нагрузки работал на отдельной клиентской машине, время реагирования включает время на передачу и подтверждение приема по сети. Рисунок 4. Подробные результаты выполнения транзакций при 200 пользователях.
При необходимости драйвер рабочей нагрузки можно настроить на вывод подобной сводной информации по транзакциям через каждые n минут во время тестирования. Эта особенность позволила нам удостовериться в том, что пропускная способность все время остается стабильной. Драйвер рабочей нагрузки также может вычислять 90-й, 95-й или 99-й процентиль времени отклика транзакций. Процентили полезны, если вы хотите удостовериться в том, что 90, 95 или 99 процентов времени отклика транзакций находятся ниже определенного порогового уровня. Напомним, что драйвер рабочей нагрузки доступен бесплатно в виде открытого исходного кода и может использоваться для выполнения рабочей нагрузки SQL, SQL/XML или XQuery любого определенного вами вида. Он представляет собой универсальный инструмент для всех видов тестирования производительности баз данных. Производительность буферных пулов при "самонастройке управления памятью"Суммарный размер всех буферных пулов, отрегулированный самонастраивающимся диспетчером памяти DB2, достиг 46 ГБ (из 64 ГБ физической памяти). Поскольку размер базы данных после сжатия составлял примерно 440 ГБ, соотношение размеров буферных пулов и базы данных составило 10,5 процентов (46 ГБ/440 ГБ). На рисунке 5 показано, что буферные пулы для индексов custacc и order имели результативность поиска от 95 до 100 процентов. Результативность поиска для таблиц custacc и order находилась в пределах от 60 до 70 процентов. Без сжатия DB2 эти показатели результативности поиска были бы ниже, а производительность - хуже. Рисунок 5. Результативность поиска в буферных пулах.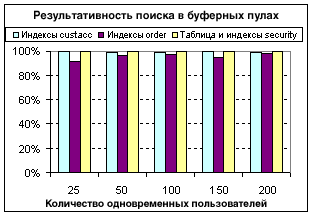 Производительность готового продукта DB2Насколько же трудно настроить DB2 для получения производительности, достигнутой нами при проведении данного теста? Например, действительно ли необходимо иметь пять отдельных табличных пространств и буферных пулов для разных таблиц и индексов? Можем ли мы достичь аналогичной производительности с использованием гораздо более простых настроек базы данных, чем тот сценарий DDL, который мы использовали изначально? В попытке ответить на эти вопросы мы повторили эталонное тестирование и сконфигурировали базу данных DB2, выполнив всего четыре простых шага:
Данные шаги показаны на рисунке 6. Заметьте, что эта база данных использует всего одно установленное по умолчанию табличное пространство и один установленный по умолчанию буферный пул для всех таблиц и индексов. С такой настройкой смешанная рабочая нагрузка при 200 пользователях достигла 6368 транзакций в секунду, что всего на 6 процентов меньше, чем показатель 6763 транзакции в секунду, которого мы достигли при более детальном конфигурировании базы данных. Этот результат показывает, что высокая производительность не всегда требует точной экспертной настройки базы данных и что внутренние возможности настройки DB2 работают в высшей степени качественно. Рисунок 6. Конфигурирование базы данных с помощью пяти команд. Масштабируемость на многоядерных ЦПНа рисунке 7 сравнивается пропускная способность, измеренная в трех разных случаях. Эти случаи представлены ниже (слева направо):
В первом тесте четырехъядерные ЦП Intel Xeon 7300 нагружаются 150 одновременными пользователями. Рабочая нагрузка достигает максимальной пропускной способности 4558 транзакций в секунду при использовании ресурсов ЦП на 99,3 %. В тесте 2 переход с четырехъядерных (Xeon 7300) на шестиядерные (Xeon 7400) ЦП увеличивает частоту транзакций для 150 пользователей на 42 процента при использовании ресурсов ЦП всего на 84,7 процента. Поскольку машина не нагружена, в тесте 3 количество пользователей увеличивается до 200. Это обеспечивает использование ресурсов ЦП на 95,2 процента и 6763 транзакций в секунду (прирост производительности шестиядерных процессоров по сравнению с четырехъядерными составляет 48 процентов). Прирост производительности в 1,42 и 1,48 раза, показанный на рисунке 7, поражает воображение, поскольку при учете лишь количества ядер и тактовой частоты можно было бы ожидать, что ЦП Intel Xeon 7400 будут иметь производительность в 1,36 раза выше, чем ЦП Intel Xeon 7300. Дополнительное увеличение быстродействия главным образом объясняется наличием кэша 3-го уровня объемом 16 МБ, который является нововведением в процессорах Intel Xeon серии 7400. В равной степени важным является тот факт, что ЦП Intel Xeon 7400 обеспечивают более высокую производительность при сохранении того же уровня потребления мощности, что и у ЦП Intel Xeon 7300. Повышение производительности в расчете на ватт потребляемой мощности важно для того, чтобы сделать вычисления более экономичными и рентабельными. Рисунок 7. Масштабируемость при переходе с четырехъядерных на шестиядерные ЦП Intel.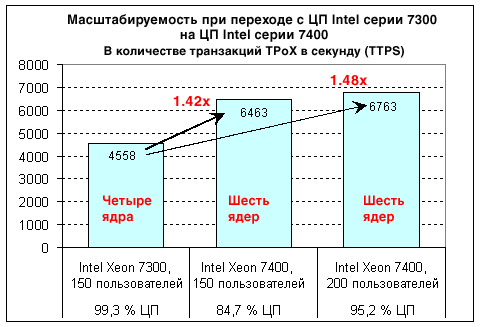 Производительность операций вставки XMLВставка строк в пустую таблицу с пустыми индексами может выполняться быстрее, чем вставка в таблицу, которая уже содержит большой объем данных. Для получения значимой оценки производительности операций вставки XML мы измеряли рабочую нагрузку только операций вставки в заполненную базу данных объемом 1 ТБ. Тест вставки предусматривал добавление 2 миллионов документов XML в таблицу custacc и 3 миллионов документов в таблицу order (см. рисунок 8). Обе таблицы имеют два индекса XML. Проверка схемы XML не проводилась. Документы custacc вставлялись со скоростью примерно 4900 документов в секунду, что составляет ~100 ГБ/ч. Менее объемные документы order вставлялись со скоростью 11900 документов в секунду, или 69 ГБ/ч. Для документов обоих типов тесты вставки предусматривали использование 600 одновременных пользователей, которые выдавали операторы вставки без пауз на обдумывание. Фиксация выполнялась после каждой отдельной вставки. Менее частые фиксации или использование утилиты контроля нагрузки DB2 могут обеспечивать еще более высокие скорости ввода XML. Рисунок 8. Производительность инкрементных операций вставки XML.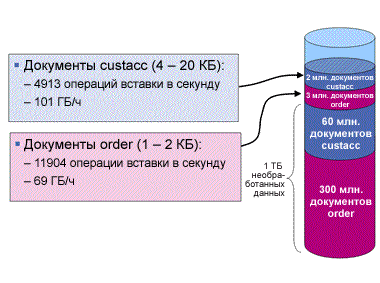 Полученные урокиКакие же уроки мы извлекли из изучения производительности XML объемом 1 ТБ? Помимо фактических результатов тестирования производительности и масштабируемости, ценными являются еще несколько наблюдений. Один из полученных уроков заключается в том, что точная настройка DB2 для обработки транзакций на основе XML не вызывает больших затруднений. Была доказана исключительная успешность стратегии использования автономных функций и функций самонастройки DB2. За разумный период времени нам не удалось достичь более высокой производительности при ручной настройке по сравнению с автоматической. Необходимым предварительным условием достижения хорошей производительности являются сбалансированные аппаратные средства, т. е. использование "правильного" соотношения между количеством ядер ЦП, объемом оперативной памяти и количеством дисков. При использовании 24 ядер, 64 ГБ памяти и 120 дисков для хранения данных наша тестовая система имела по 5 дисков и по 2,66 ГБ памяти на одно ядро. Оптимальное соотношение зависит от рабочей нагрузки. В условиях смешанной рабочей нагрузки TPoX мы наблюдали в среднем по 1,7 запроса физического ввода-вывода на одну транзакцию. Таким образом, при пиковой частоте 6763 транзакции в секунду система хранения была вынуждена выдерживать примерно 11500 операций ввода-вывода в секунду (IOPS). В соответствии с эмпирическим правилом о том, что современный диск SCSI может поддерживать примерно 100 IOPS при умеренно малых задержках, для предотвращения ситуаций с нехваткой ресурсов ввода-вывода и обеспечения высокого коэффициента использования ресурсов ЦП необходимо примерно 115 дисков. Сжатие DB2 играло критически важную роль. Без сжатия для достижения той же производительности потребовалось бы больше дисков и памяти. Сжатие обеспечило сокращение требуемого количества ресурсов ввода-вывода, и это преимущество значительно перевешивает потребность в дополнительном количестве циклов ЦП для сжатия и распаковки данных. Для понимания характеристик производительности базы данных крайне полезными оказались контроль моментальных снимков DB2 и создание моментальных снимков через одинаковые промежутки времени, например через каждые 5 минут. Таким образом, собираемые данные позволяют вам анализировать характеристики ввода-вывода и очистки страниц с течением времени. Для систем Linux и UNIX DB2 9.5 имеет модель процессов, в корне отличающуюся от DB2 9.1. В то время как DB2 9.1 порождает отдельный процесс для каждого агента, DB2 9.5 работает в качестве отдельного процесса, имеющего по одному потоку на агента.Наши результаты подтверждают, что механизм организации поточной обработки DB2 использует ресурсы многоядерных ЦП с высокой степенью эффективности и достигает хороших показателей увеличения быстродействия при переходе с 4-ядерных процессоров Intel Xeon на 6-ядерные. Ссылки по теме
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| О нас |
|
Интернет-магазин ITShop.ru предлагает широкий спектр услуг информационных технологий и ПО.
На протяжении многих лет интернет-магазин предлагает товары и услуги, ориентированные на бизнес-пользователей и специалистов по информационным технологиям. Хорошие отзывы постоянных клиентов и высокий уровень специалистов позволяет получить наивысший результат при совместной работе. В нашем магазине вы можете приобрести лицензионное ПО выбрав необходимое из широкого спектра и ассортимента по самым доступным ценам. Наши менеджеры любезно помогут определиться с выбором ПО, которое необходимо именно вам. Также мы проводим учебные курсы. Мы приглашаем к сотрудничеству учебные центры, организаторов семинаров и бизнес-тренингов, преподавателей. Сфера сотрудничества - продвижение бизнес-тренингов и курсов обучения по информационным технологиям.
|
|
119334, г. Москва, ул. Бардина, д. 4, корп. 3 +7 (495) 229-0436 shopadmin@itshop.ru |
|
© ООО "Interface Ltd." Продаем программное обеспечение с 1990 года |

 Рабочая нагрузка TPoX состоит из 17 транзакций, перечисленных в таблице 1. Их относительный вес в структуре транзакций указан в крайнем правом столбце. Операции вставки, обновления и удаления составляют 30 процентов рабочей нагрузки; запросы - 70 процентов рабочей нагрузки. В транзакциях I2, U2 и U4 выполняется проверка схемы XML.
Рабочая нагрузка TPoX состоит из 17 транзакций, перечисленных в таблице 1. Их относительный вес в структуре транзакций указан в крайнем правом столбце. Операции вставки, обновления и удаления составляют 30 процентов рабочей нагрузки; запросы - 70 процентов рабочей нагрузки. В транзакциях I2, U2 и U4 выполняется проверка схемы XML.