| +7 (495) 229-0436 | shopadmin@itshop.ru | 119334, г. Москва, ул. Бардина, д. 4, корп. 3 |
|
|
Разбиение веб-страниц на семантические блоки04.03.2014 15:52
dkuser
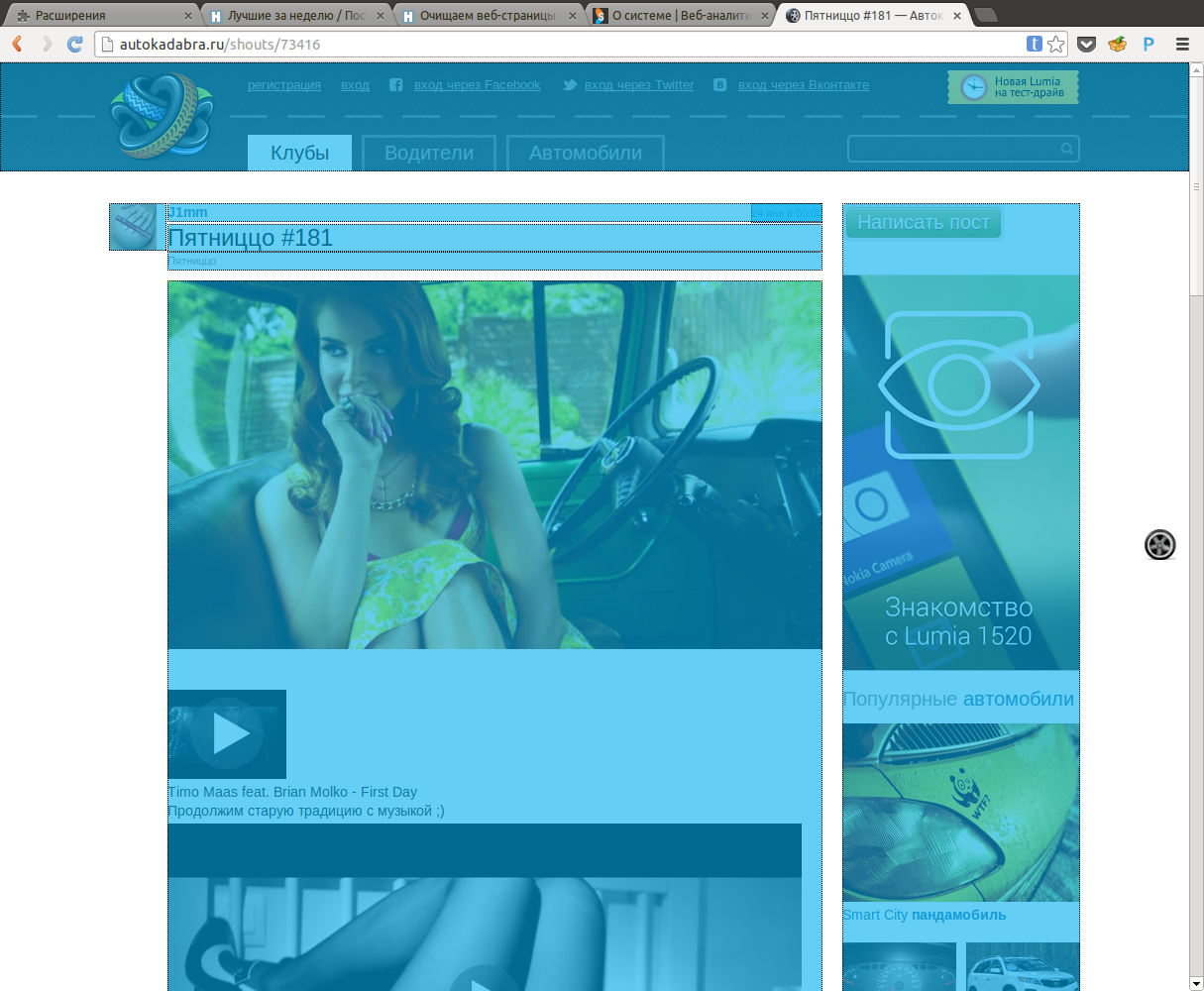
 Пример работы алгоритма на сайте Автокадабра.
ЗадачаНаверное, все знают про сервис "Вебвизор", который позволяет записывать действия посетителей вашего сайта и просматривать их в режиме видео. Инструмент интересный, но когда на сайте много посетителей, составить картину жизни сайта проблематично, каждый ролик не посмотришь, и сгруппировать их нельзя. Гораздо полезней отследить взаимодействие посетителей с сайтом, выяснить чем живёт сайт, с возможностью охватить одновременно множество посетителей. В итоге, появилась идея записывать информацию в виде осмысленного списка действий посетителей:
Запись состоит из двух частей: блок в котором происходит действие посетителя и само действие, например - выделение текста " времени " в блоке " Одна из ключевых особенностей ... ". Для этого описания необходимо определить блок на странице и его имя. Если с именем было более-менее понятно, то над выделением блоков пришлось подумать. Варианты решенияПервый шаг - поиск существующих решений этой задачи. Один из них "Метод разбиения веб-страниц на семантические блоки с целью выявления схожих документов" (Д. И. Косинов. Воронежский государственный университет). Здесь определялся наибольший элемент и вынимался из страницы, и так до тех пор пока оставался контент. Чтобы не вытащить сразу весь <BODY>, в функцию веса был введён показатель глубины узла с целью выделять блоки по возможности на более низких уровнях. В процессе реализации и тестирования, выяснилось что проблема возникает в нескольких местах, во первых, требуется правильно подобрать коэффициенты для функции веса, во-вторых, после удаления контента на странице остаются "дырки", и следующий блок получается рваным, например блок 4 на рисунке. 
После этого начали прорабатываться свои решения, одним из вариантов было выделять блоки с определенной длиной контента, который оказался не совсем удачным. Как-то вечером пришло другое решение, ставшее окончательным. Суть была проста, зачем искать семантические блоки на странице, когда вёрстка в основном итак объединяет блоки по смыслу, необходимо только определить до какого уровня разбивать блоки и какие именно.
Окончательный вариантАлгоритм разбиения веб-страницы на блокиОсновная идея алгоритма заключается в предположении, что объединённые общим смыслом элементы веб-страницы зачастую имеют общего родителя в дереве DOM. Экспериментальным путём было установлено, что число обособленных смысловых блоков на странице в среднем равно квадратному корню из числа элементов на самом нижнем уровне дерева DOM (т. е. квадратному корню из числа элементов, не имеющих дочерних). Коротко алгоритм можно описать следующими шагами:
Пример функции разбиения Вес элементаВес определят, какой следующий элемент будет разбит на дочерние, он учитывает как размер содержимого, так и площадь элемента, Вес_элемента = log(длина_текста * 0.1 + 1.01) * log(площадь * 0.9 + 0.11). Больший приоритет отдаётся площади элемента, магические числа 1.01 и 0.11 ограничивают логарифм, чтобы вес оставался положительным числом. Пустые узлы алгоритмом исключаются, поэтому минимальные значения размеров текста и площади составляют единицу. Для объектов, которые не могут содержать внутри текст (изображения, встроенные объекты и т. д.), параметр длина_текста считается как площадь / 140 (140 - среднее значение площади одного символа текста). При подсчёте длины текста исключаются повторяющиеся пробелы, а также не учитывается внутренний текст элементов <STYLE> и <SCRIPT>.
Название блокаПоиск названия блока достаточно прост:
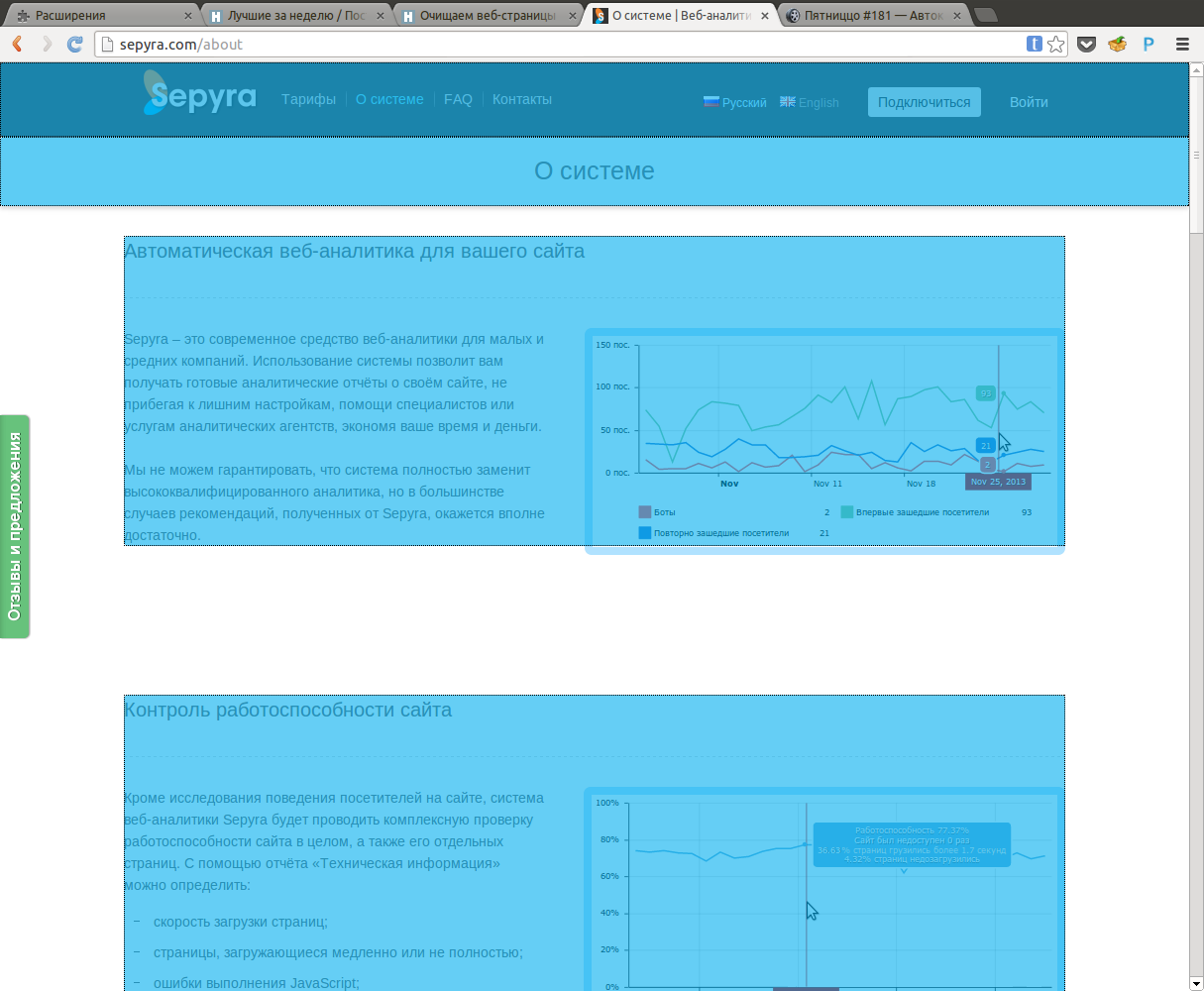
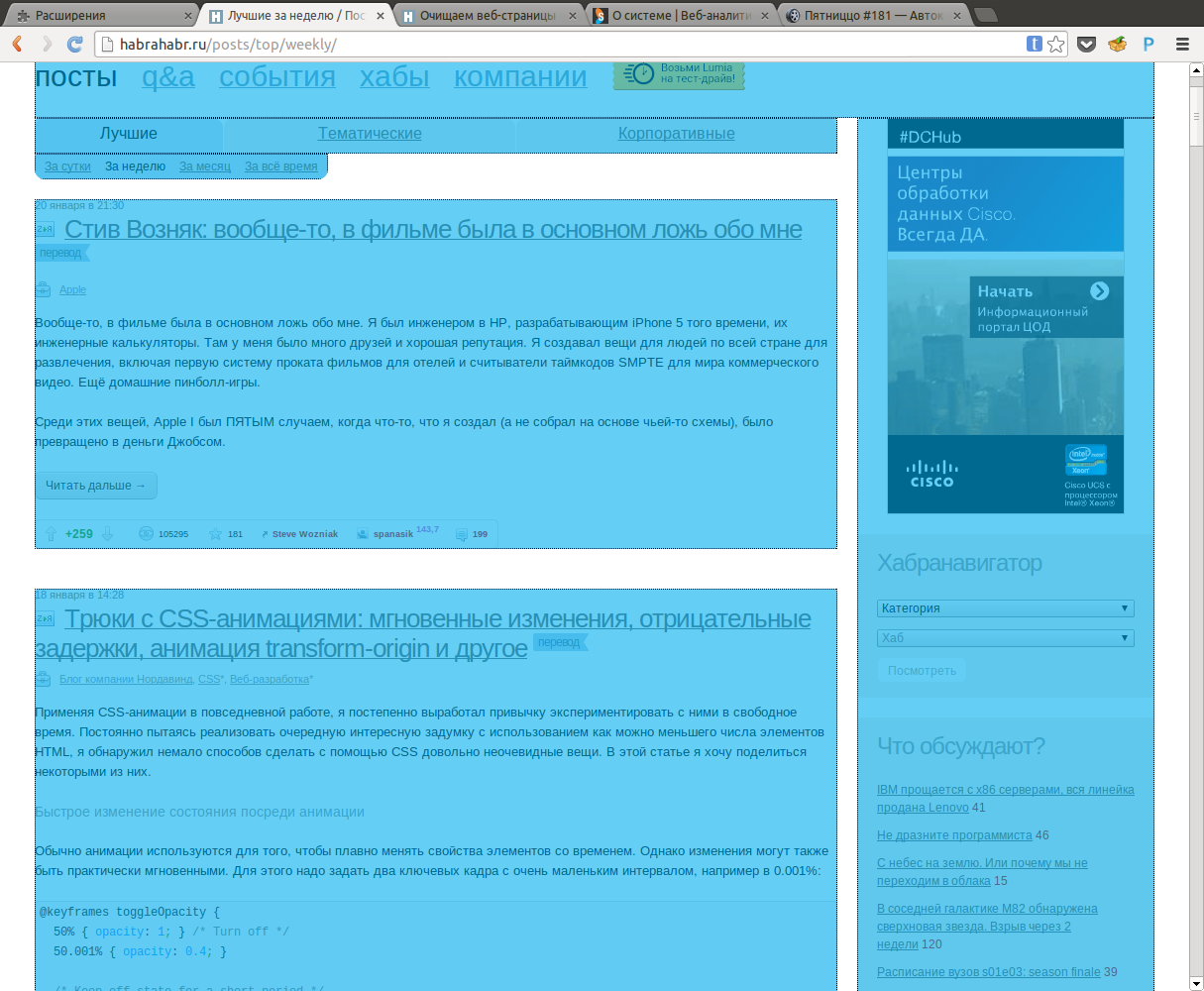
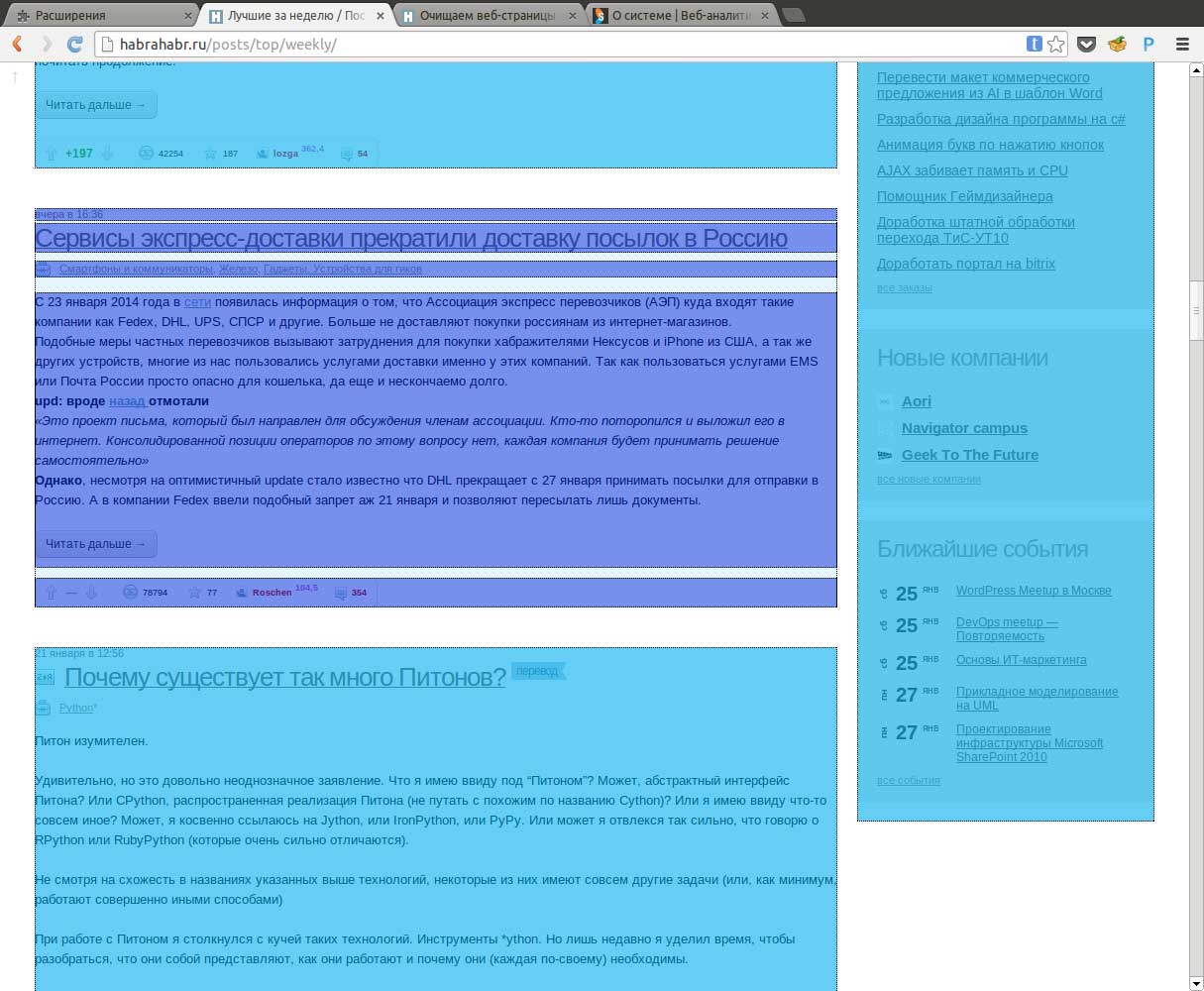
Что получилосьНиже представлены примеры, того, что вышло в итоге (картинки кликабельны): Автокадабра Sepyra Список статей на Хабре По такому же алгоритму, возможно разделить блок на подблоки:
В живую можно посмотреть здесь, также и другие примеры.
Похожие решенияТакже нашлось множество патентов, по данной тематике, может кому пригодится.
ВыводАлгоритм получился рабочим, достаточно простым и понятным, что немаловажно. Из минусов, не слишком устойчив, небольшие изменения кода он переживёт, но при добавлении виджетов на страницу, других изменениях структуры документа, блоки могут разбиться иначе. Ссылки по теме |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| О нас |
|
Интернет-магазин ITShop.ru предлагает широкий спектр услуг информационных технологий и ПО.
На протяжении многих лет интернет-магазин предлагает товары и услуги, ориентированные на бизнес-пользователей и специалистов по информационным технологиям. Хорошие отзывы постоянных клиентов и высокий уровень специалистов позволяет получить наивысший результат при совместной работе. В нашем магазине вы можете приобрести лицензионное ПО выбрав необходимое из широкого спектра и ассортимента по самым доступным ценам. Наши менеджеры любезно помогут определиться с выбором ПО, которое необходимо именно вам. Также мы проводим учебные курсы. Мы приглашаем к сотрудничеству учебные центры, организаторов семинаров и бизнес-тренингов, преподавателей. Сфера сотрудничества - продвижение бизнес-тренингов и курсов обучения по информационным технологиям.
|
|
119334, г. Москва, ул. Бардина, д. 4, корп. 3 +7 (495) 229-0436 shopadmin@itshop.ru |
|
© ООО "Interface Ltd." Продаем программное обеспечение с 1990 года |