| +7 (495) 229-0436 | shopadmin@itshop.ru | 119334, г. Москва, ул. Бардина, д. 4, корп. 3 |
|
|
Как справиться с PAGELATCH при больших INSERT-нагрузках08.12.2009 17:50
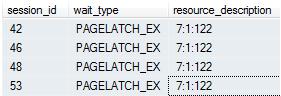
Введение Недавно, мы проводили лабораторные испытания в Microsoft Enterprise Engineering Center, при которых использовалась большая рабочая нагрузка, характерная для OLTP систем. Целью этой лабораторной работы было определить, что случится при увеличении числа процессоров с 64 до 128, при обслуживании Microsoft SQL Server интенсивной рабочей нагрузки (примечание: эта конфигурация была ориентирована на релиз Microsoft SQL Server 2008 R2). Рабочая нагрузка представляла собой хорошо распараллеленные операции вставки, направляемые в несколько больших таблиц. Диагностика проблемы Когда в sys.dm_os_wait_stats наблюдается большое число PAGELATCH, с помощью sys.dm_os_waiting_tasks можно определить сессию и ресурс, который задача ожидает, например, с помощью этого сценария: SELECT session_id, wait_type, resource_description Пример результата:
В столбце resource_description указаны местоположения страниц, к которым ожидают доступ сессии, местоположение представлено в таком формате: <database_id>:<file_id>:<page_id> Опираясь на значения в столбце resource_description, можно составить довольно сложный сценарий, который предоставит выборку всех попавших в список ожидания страниц: SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms Сценарий показал, что ожидаемые страницы относятся к кластеризованному индексу, определённому первичным ключом таблицы с представленной ниже структурой: CREATE TABLE HeavyInsert ( Что происходит, почему возникает очередь ожиданий к страницам данных индекса - всё это будет рассмотрено в этой технической заметке. Основная информация Чтобы определить, что происходит с нашей большой OLTP-нагрузкой, важно понимать, как SQL Server выполняет вставку в индекс новой строки. При необходимости вставки в индекс новой строки, SQL Server будет следовать следующему алгоритму внесения изменений:
В итоге, страница должна будет быть сброшена на диск процессом контрольной точкой или отложенной записи. Решение Всегда, когда несколько потоков получают синхронный доступ к одному и тому же ресурсу, может проявиться описанная выше проблема. Стандартное решение состоит в том, чтобы создать больше ресурсов конкурентного доступа. В нашем случае, таким конкурентным ресурсом является последняя страница В-дерева. CREATE PARTITION FUNCTION pf_hash (INT) AS RANGE LEFT FOR VALUES (0,1,2) Представленный выше пример использует четыре секции. Число необходимых секций зависит от числа активных процессов, выполняющих операции INSERT в описанную выше таблицу. Есть некоторая сложность в секционировании таблицы с помощью хэш-столбца, например, в том что всякий раз, когда происходит выборка строк из таблицы, будут затронуты все секции. Это означает, что придётся обращаться более чем к одному В-дереву, т.е. не будет отброшенных оптимизатором за ненадобностью ненужных секций. Будет дополнительная нагрузка на процессоры и некоторое увеличение времени ожиданий процессоров, что побуждает минимизировать число планируемых секций (их должно быть минимальное количество, при котором не наблюдается PAGELATCH). В рассматриваемом нами случае, в системе нашего клиента имелось достаточно много резерва в утилизации процессоров, так что было вполне возможно допустить небольшую потерю времени для инструкций SELECT, и при этом увеличить до необходимых объёмов норму инструкций INSERT. CREATE TABLE HeavyInsert_Hash( С помощью столбца HashID, вставки в четыре секции будут выполняться циклически. CREATE UNIQUE CLUSTERED INDEX CIX_Hash Используя новую схему таблицы с секционированием вместо первоначального варианта таблицы, мы сумели избавиться от очередей PAGELATCH и повысить скорость вставки. Этого удалось достичь за счёт балансировки вставки между несколькими секциями и высокого параллелизма. Вставка происходит в несколько страниц, и каждая страница размещается в своей собственной структуре В-дерева. Для нашего клиента удалось повысить производительность вставки на 15 процентов, и справится с большой очередью PAGELATCH к горячей странице индекса одной таблицы. Но при этом удалось также оставить достаточно большой резерв циклов процессоров, что оставило возможность сделать аналогичную оптимизацию для другой таблицы, тоже с высокой нормой вставки. Пример: Чтобы отбросить ненужные секции, можно внести следующие изменения в сценарий: SELECT * FROM HeavyInsert_Hash Который после изменений будет выглядеть так: SELECT * FROM HeavyInsert_Hash Исключение оптимизатором ненужных секций по значению хэша не будет вам ничего стоить, если только не считать большой платой за это увеличение на один байт каждой строки кластеризованного индекса. Ссылки по теме |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| О нас |
|
Интернет-магазин ITShop.ru предлагает широкий спектр услуг информационных технологий и ПО.
На протяжении многих лет интернет-магазин предлагает товары и услуги, ориентированные на бизнес-пользователей и специалистов по информационным технологиям. Хорошие отзывы постоянных клиентов и высокий уровень специалистов позволяет получить наивысший результат при совместной работе. В нашем магазине вы можете приобрести лицензионное ПО выбрав необходимое из широкого спектра и ассортимента по самым доступным ценам. Наши менеджеры любезно помогут определиться с выбором ПО, которое необходимо именно вам. Также мы проводим учебные курсы. Мы приглашаем к сотрудничеству учебные центры, организаторов семинаров и бизнес-тренингов, преподавателей. Сфера сотрудничества - продвижение бизнес-тренингов и курсов обучения по информационным технологиям.
|
|
119334, г. Москва, ул. Бардина, д. 4, корп. 3 +7 (495) 229-0436 shopadmin@itshop.ru |
|
© ООО "Interface Ltd." Продаем программное обеспечение с 1990 года |